I was surprised by results than comparing Parquet, Avro, JSON, and CSV for both storage and speed
tl;tr
Each file format has its own place in data engineering. You should choose one based on your project or workload.
preparing my data
I have pulled my data set from here
For my testing, I’ll be using only a couple of columns so I have transformed the original file format to a new one.
{
'country': 'Lithuania',
'city': row['CITY'],
'postcode': int(row['POSTCODE'].replace("LT-", "") if row['POSTCODE'] != ' ' else 0),
'street': f"{' '.join(row['STREET'].split(' ')[1:])} {row['STREET'].split(' ')[0]}",
'full_address': build_full_address(row),
'longitude': float(row['LON']),
'latitude': float(row['LAT'])
}
I have added full_address column which joins street, city, and postcode.
Data set has 1036250 rows
generating data files
same dataset different formats
In the first step I took the original data and wrote it into different file formats:
| Format | Size |
|---|---|
| csv | 106MB |
| json | 222MB |
| avro | 24MB |
| parquet | 32MB |
Both CSV and JSON are losing a lot compared to Avro and Parquet, however, this is expected because both Avro and Parquet are binary formats (they also use compression) while CSV and JSON are not compressed.
To make this more comparable I will be applying compression for both JSON and CSV.
Compression makes a difference
| Format | Original | Compressed |
|---|---|---|
| csv | 106MB | 20MB |
| json | 222MB | 22MB |
| avro | 24MB | 24MB |
| parquet | 32MB | 32MB |
Moving forward I’ll be using compressed files for comparison
shuffle some data
My initial data set was already sorted, I will shuffle it to make a more realistic.
| Format | Original | Shuffle |
|---|---|---|
| csv | 20MB | 34MB |
| json | 22MB | 40MB |
| avro | 24MB | 45MB |
| parquet | 32MB | 44MB |
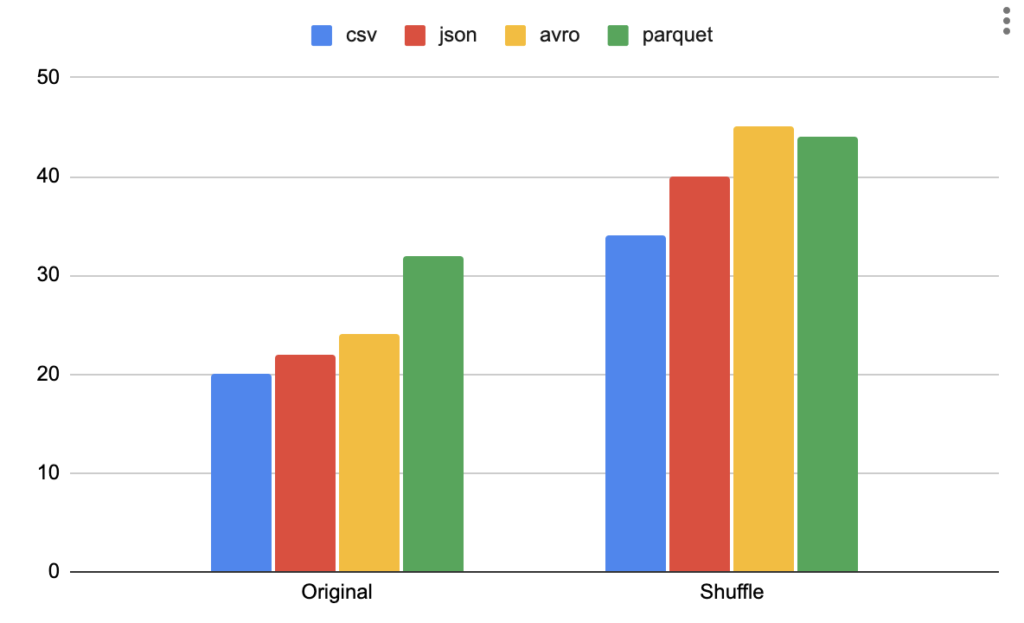
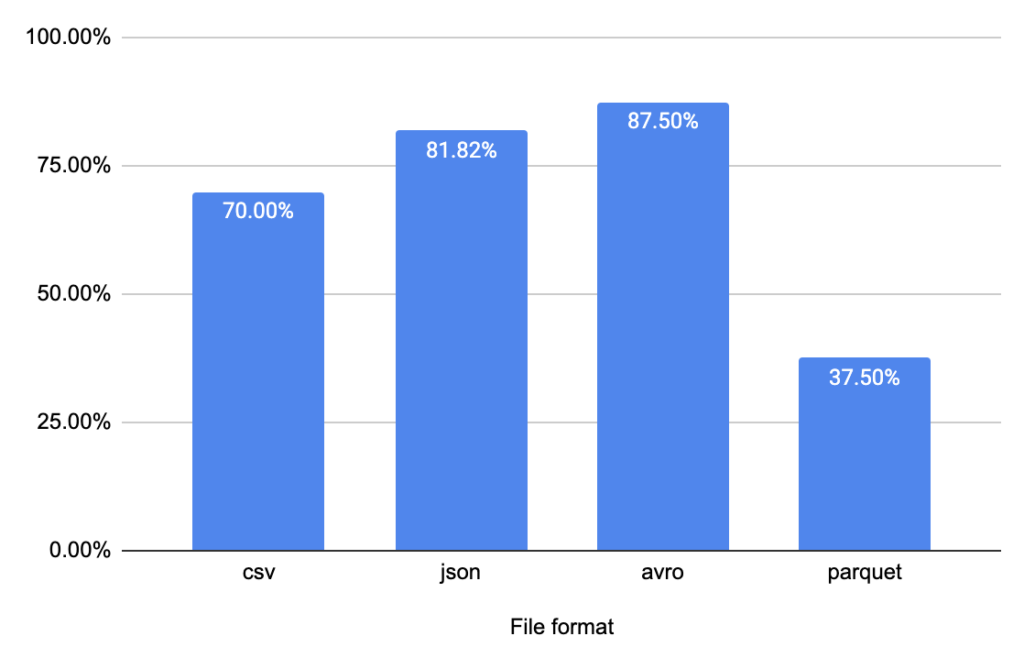
Shuffle has affected the overall size for all formats. I surprised it Avro has the most significant impact. It increased by 88%. Parquet is a clear winner here with data increase only by 38%
5x
For speed testing, I wanted to have more data. So I replicate data 5 times and the final dataset was again shuffled.
| Format | Original | Shuffle | 5x |
|---|---|---|---|
| csv | 20MB | 34MB | 168MB |
| json | 22MB | 40MB | 198MB |
| avro | 24MB | 45MB | 222MB |
| parquet | 32MB | 44MB | 215MB |
No surprises here…
query speed
For my testing, I’m using Apache Spark. I load all data types into the data frame and register it as TempView.
we will be testing queries… we must have tables and SQL!!!
#parquet
df = spark.read.parquet('data/parquet/data_5x.parquet')
df.createOrReplaceTempView('source_table')
#csv
df = spark.read.format("csv").option("header","true").load('data/csv/data_5x.csv.gz')
df.createOrReplaceTempView('source_table')
#json
df = spark.read.option("multiline", "true").json("data/json/data_5x.json.gz")
df.createOrReplaceTempView('source_table')
#avro
df = spark.read.format("avro").load("data/avro/data_5x.avro")
df.createOrReplaceTempView('source_table')
I came up with a list of queries.
if you have a query suggestion – please leave it in the comments on social media.
queries:
#Q1:
select count(*) as cnt from source_table
#Q2:
select count(distinct full_address) as cnt from source_table
#Q3:
select count(distinct full_address) as cnt from source_table where city = 'Vilnius'
#Q4:
select city, count(distinct full_address) as cnt from source_table group by 1 order by cnt desc
#Q5:
select count(*) from source_table where city = 'Vilnius' and street = 'Kauno gatvė'
#Q6:
select count(*) from source_table where full_address like '%Liep%'
Results:
| Query | csv | json | avro | parquet |
|---|---|---|---|---|
| q1 | 04.711 | 11.782 | 00.498 | 00.103 |
| q2 | 12.945 | 16.360 | 01.986 | 03.132 |
| q3 | 09.654 | 14.645 | 00.795 | 01.240 |
| q4 | 14.365 | 18.031 | 02.795 | 04.463 |
| q5 | 08.252 | 14.008 | 00.480 | 00.628 |
| q6 | 08.831 | 14.004 | 00.544 | 00.977 |
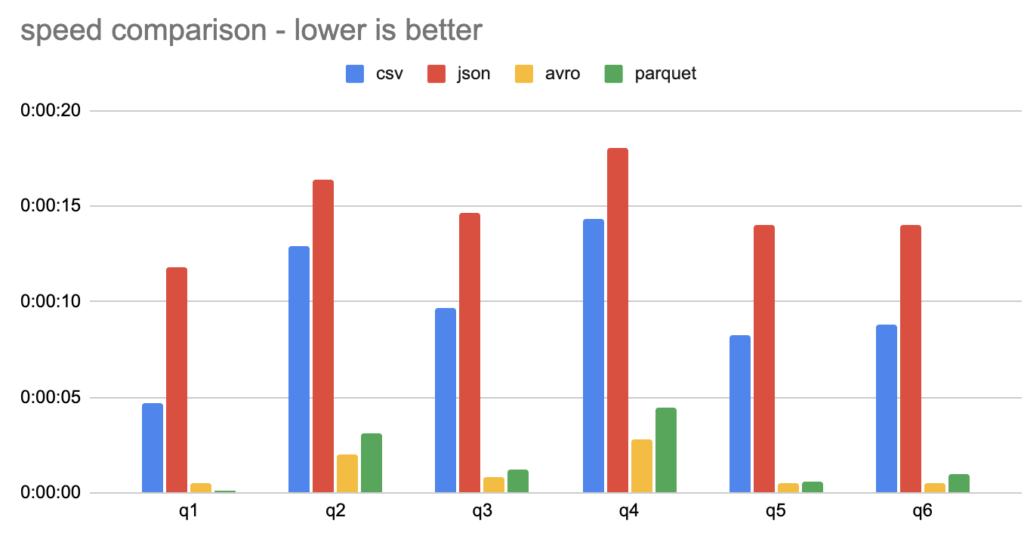
Parquet and Avro are clear winners for running queries
summary
CSV – can be compressed very well. This format’s ancient – so you should not have a problem reading it.
I would choose this format for moving data via FTP or email.
Avro – I knew nothing about it before starting my tests, it is a row-based format while parquet is columnar.
I think it would be perfect for storing data consumed by Kafka
JSON – having schema in each row is not efficient… for it, you pay with speed and size. However at the same time if your schema is evolving you do not need to do anything.
I still like this format because of how easy it is to deal with it
Parquet – I was expecting a little bit more from it (was really surprised by Avro’s performance).
I’m still shocked it was beaten by Avro 😀
I think all of these formats will continue to be used.